1 AutoML¶
1.1 Introduction¶
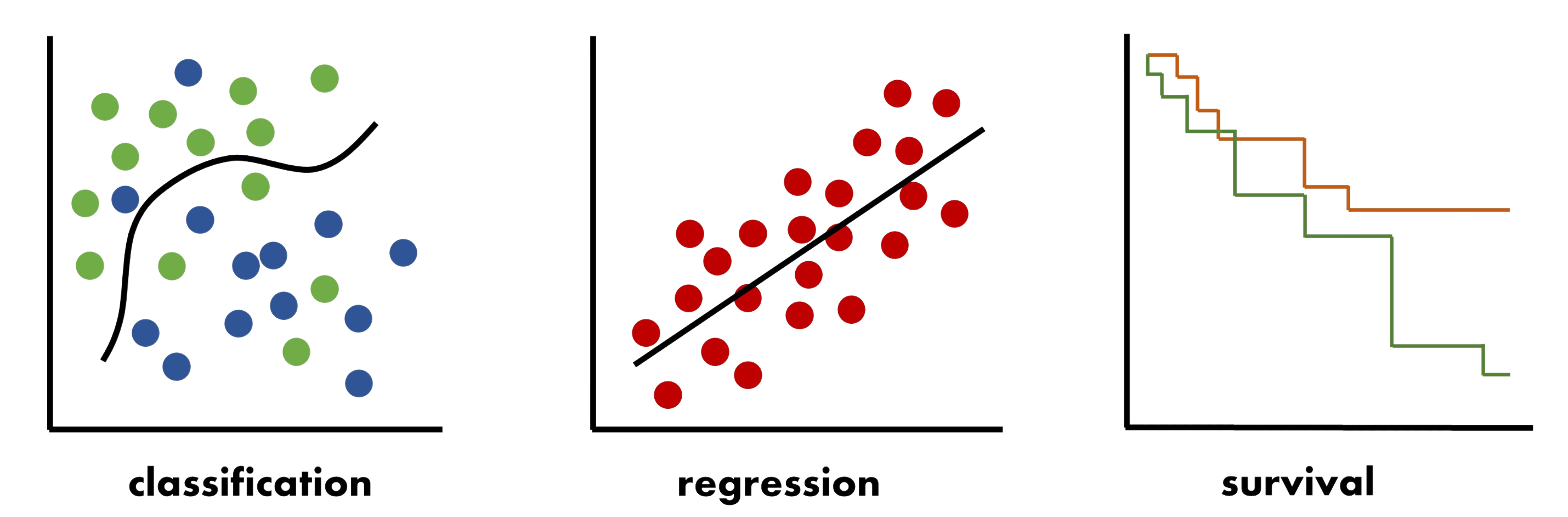
The GGD AutoML is an automatic pipeline to train, test and select machine learning models on specified input feature matrix data and response variables and select biological significant markers. AutoML supports three types of response variables: 1) categorical data, 2) continuous data, 3) time-to-event data. Therefore autoML is able to conduct three types of machine learning analysis: 1) classification (binary or multi-class), 2) regression, 3) survival data.
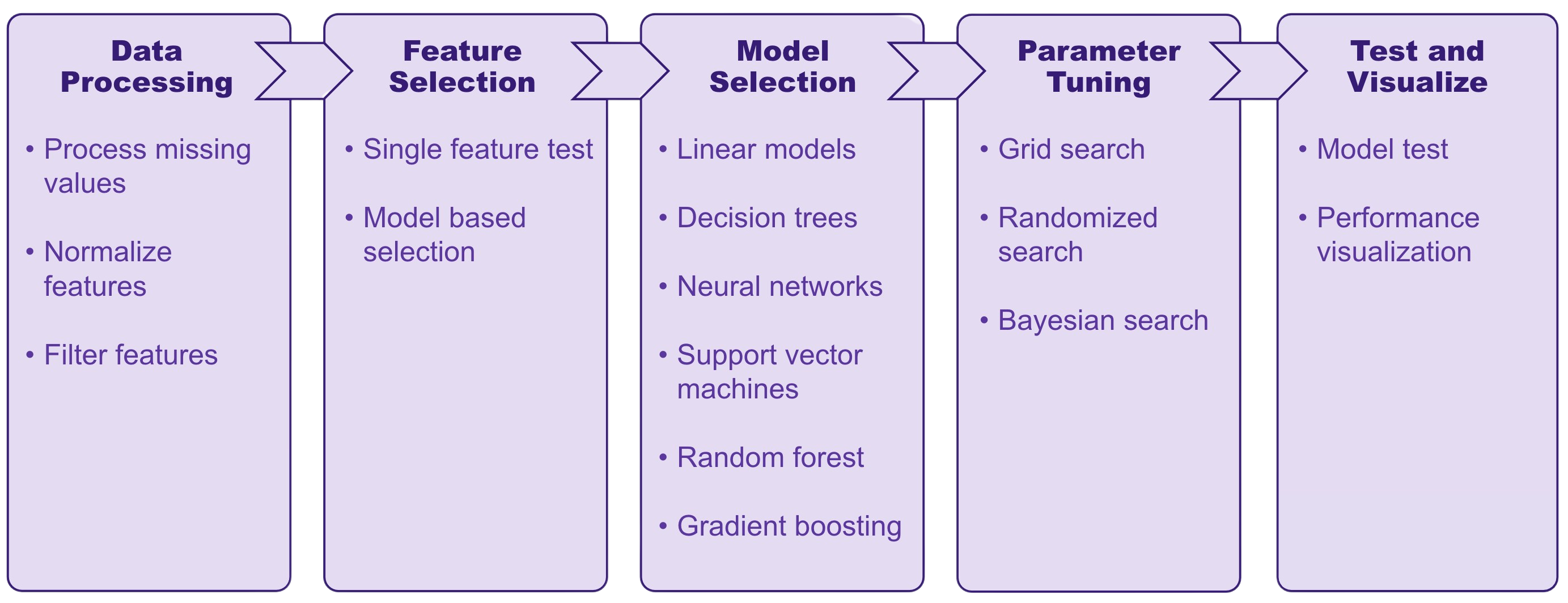
1.2 Workflow¶
The workflow of autoML consists of five main steps: 1. Data preprocessing This includes various feature processing and filtering procedures to retain valid features and scale them for proper machine learning analysis. Data is splited for model training, validation and testing. 2. Feature selection This step is to select candidate features for machine learning training and validation. We incorporates both statistical significance test based single feature selection methods and embedded model based feature selections methods. 3. Model selection We train and validate various machine learning models, and select the best performing model on the data. 4. Parameter tuning We apply various parameter tuning approaches to select best set of parameters for machine learning model. 5. Test and visualization Model is evaluated in test data and performance is visualized.